Why Dapr? Simplifying Microservices in the Real World


Introduction: Microservices Solve One Problem and Create Another
Most applications start simple.
You build one application, keep the code in one place, deploy it as one unit, and connect it to one database. For a while, that is not a problem. In fact, it is often the right place to start.
But as the application grows, the same structure that once felt simple can start to slow you down.
A small change may require redeploying the whole system. One busy feature may force you to scale the entire application. More teams working in the same codebase may create more merge conflicts, more coordination, and more risk. Over time, the monolith can become harder to change safely.
That is why many teams move toward microservices.
Instead of one large application, they split the system into smaller services. Each service owns a smaller part of the business. Each service can be developed, deployed, and scaled more independently.
That sounds like freedom.
And sometimes it is.
But microservices also create a new problem: you are no longer just building an application. You are building a distributed system.
Now your services need to find each other. They need to call each other reliably. They need retries, timeouts, state management, secrets, observability, pub/sub messaging, and configuration. You may solve those problems once, then solve them again in another service, then solve them again in another language or team.
This is where microservices can become painful.
The business logic may be small, but the infrastructure plumbing around it keeps growing.
Dapr, the Distributed Application Runtime, was created to help with that problem.
Dapr does not remove the complexity of distributed systems entirely. Instead, it gives your services a consistent set of APIs for common distributed-system concerns.
Your application can stay focused on business logic.
Dapr handles more of the surrounding plumbing:
Service-to-service calls
State management
Publish and subscribe messaging
Bindings to external systems
Secrets
Observability
Actors
ExtensibilityThe important idea is this:
Your service talks to Dapr.
Dapr talks to the infrastructure.That means your code does not need to know every detail of the service discovery mechanism, state store, message broker, secret store, or tracing system from day one.
In this article, we will start with the problem Dapr is trying to solve. We will look at why monoliths become difficult, why microservices introduce hidden complexity, what Dapr is, how the sidecar model works, and which Dapr building blocks matter first.
By the end, Dapr should feel less like another cloud-native buzzword and more like a practical runtime layer for building distributed applications without rewriting the same infrastructure glue in every service.
Why Monoliths Start Simple
Before we talk about Dapr, it is worth being fair to the monolith.
A monolithic application is not automatically bad.
For many teams, it is the simplest and most sensible starting point. The code is in one place. The application is deployed as one unit. The database model is usually easier to understand. Local development is straightforward because you can often run the whole system on your machine.
That simplicity matters.
In the early stages of an application, a monolith can help you move quickly because there are fewer moving parts:
One codebase
One application
One deployment unit
One main database
One place to debugIf something breaks, you usually know where to look. If you need to add a feature, you can often do it without thinking about network calls, service discovery, message brokers, distributed tracing, or versioning contracts between services.
That is why starting with a monolith is often reasonable.
The problem is not the monolith itself.
The problem is what happens when the application, team, and traffic grow.
The same simplicity that helped you move quickly at the beginning can start to become a constraint later. A single deployment unit means every change can require redeploying the whole application. A single codebase means more teams are editing the same system. A single runtime means one busy feature can force you to scale everything, even if only one part of the application needs more capacity.
So the monolith starts as a strength:
Everything is together.But over time, that can become the weakness:
Everything is tied together.That is the point where teams start looking for a different architecture.
Why Teams Move to Microservices
Microservices are one answer to the “everything is tied together” problem.
Instead of building one large application, you split the system into smaller services. Each service owns a specific business capability and can be developed, deployed, and scaled more independently.
For example, an e-commerce system might be split into services like:
Catalog
Orders
Inventory
Payments
Shipping
NotificationsEach service has a clearer responsibility.
The Inventory Service manages stock. The Orders Service handles order placement. The Payments Service handles payment processing. The Notifications Service sends emails or messages.
This gives teams more flexibility.
A team working on payments does not always need to wait for a team working on inventory. A problem in one service does not always require redeploying the whole system. A high-traffic service can be scaled without scaling every other part of the application.
So the microservices promise is attractive:
Smaller codebases
Independent deployments
Independent scaling
Clearer service ownership
More flexibility in technology choicesThat is why microservices became so popular.
They can help large systems evolve faster when the organisation, application, and operational maturity are ready for them.
But the trade-off is important.
When you split one application into many services, the code may become smaller, but the system becomes more distributed.
Now the hard parts move from inside the codebase to the space between services.
A monolith asks:
How do I organise one application?A microservices architecture asks:
How do I make many applications work together reliably?That is where the hidden complexity starts.
The Hidden Cost of Distributed Systems
Microservices make individual services smaller, but they also create more edges between services.
Those edges are where the complexity starts.
In a monolith, one part of the application can often call another part in memory. It is just a function call inside the same process.
In a microservices architecture, that call may become a network request.
Now the calling service has to think about more than business logic:
Where is the other service?
What happens if the call fails?
Should I retry?
How long should I wait before timing out?
How do I secure the call?
How do I trace the request across services?The same thing happens with state.
In a small application, you may connect directly to one database. But as the system grows, different services may need different backing services:
Redis for cache or state
Cosmos DB or PostgreSQL for persistence
Service Bus or Kafka for messaging
Key Vault for secrets
Application Insights or OpenTelemetry for tracingEach one brings its own SDK, configuration model, connection details, error handling, and operational behaviour.
That is where the code can become cluttered.
The service is no longer only expressing business behaviour. It is also carrying infrastructure knowledge.
An Order Service should mostly care about order logic:
Validate the order.
Check inventory.
Place the order.
Publish an event.
Return a result.But in a distributed system, that same service can end up knowing too much about its environment:
How to find the Inventory Service
How to call it reliably
Which database stores order state
Which message broker handles order events
Where secrets are stored
How tracing is configuredThat is coupling.
The service becomes tied not only to its business responsibility, but also to the infrastructure choices around it.
This is the hidden cost of microservices.
You split the application into smaller services, but now every service may need its own infrastructure glue.
And if every team writes that glue differently, the system becomes harder to maintain:
Different retry logic
Different database access patterns
Different message broker clients
Different secret handling
Different observability conventions
Different ways to call other servicesAt that point, the problem is no longer only “how do we split the application?”
The problem becomes:
How do we stop every service from carrying so much infrastructure knowledge?That is the question Dapr is designed to answer.
What Dapr Is
Dapr stands for Distributed Application Runtime.
It is a runtime layer that helps applications use common distributed-system capabilities without wiring each one directly into the application code.
A service can talk to Dapr through simple HTTP or gRPC APIs. Dapr then handles the connection to the underlying infrastructure.
That infrastructure might be different depending on where the application runs:
Local development
→ Redis, local secrets, local tracing
Azure
→ Cosmos DB, Azure Service Bus, Azure Key Vault, Azure Monitor
Kubernetes
→ platform services, operators, service accounts, and cluster-level configurationThe important point is not that Dapr removes the infrastructure.
It does not.
The important point is that Dapr gives your application a consistent API in front of that infrastructure.
So instead of each service directly learning how to talk to every backing system, the service talks to Dapr.
The high-level model looks like this:
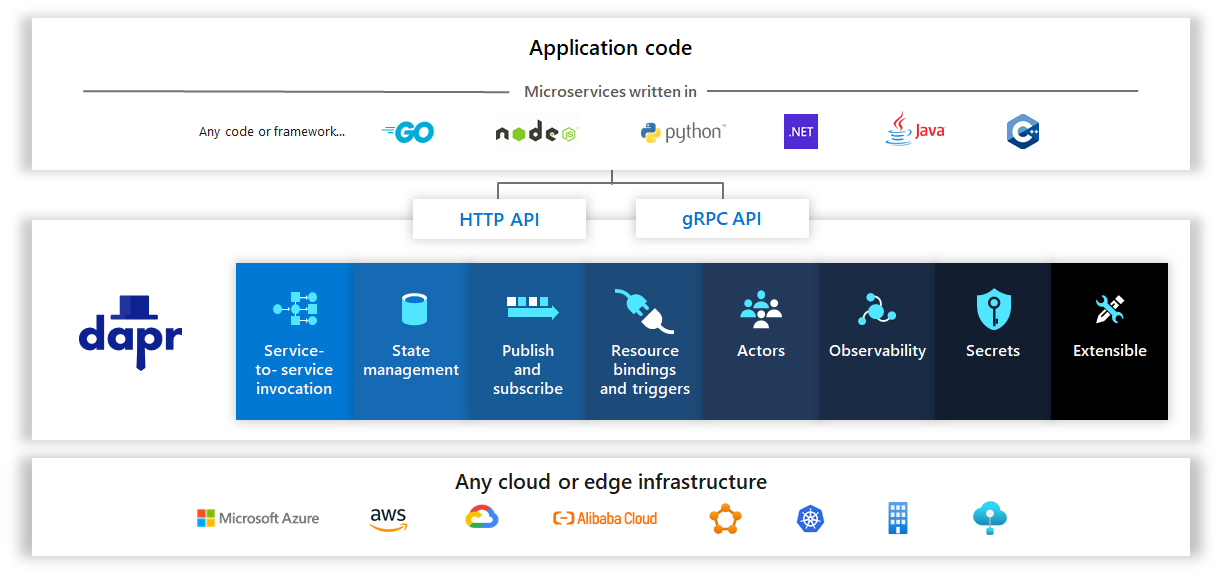
Your application code stays focused on business logic.
Dapr exposes common distributed-system capabilities through HTTP and gRPC APIs, while the underlying infrastructure can change behind those APIs.
That is why Dapr is especially useful in microservices systems. It gives teams a shared way to handle common concerns such as service invocation, state, pub/sub, secrets, and observability, without forcing every service to implement those patterns differently.
The simple model is:
Your service
→ talks to Dapr
Dapr
→ talks to the infrastructureThat is the first key idea to understand before we look at the sidecar pattern.
The Sidecar Mental Model
Dapr usually runs beside your application as a sidecar.
A sidecar is a separate process that runs next to your service and gives it extra capabilities.
Your application is still your application. It still contains your business logic. It still exposes its own endpoints. It still runs in the language and framework you chose.
Dapr does not replace that.
Instead, Dapr runs next to the service and gives it a local runtime API.
So the relationship looks like this:
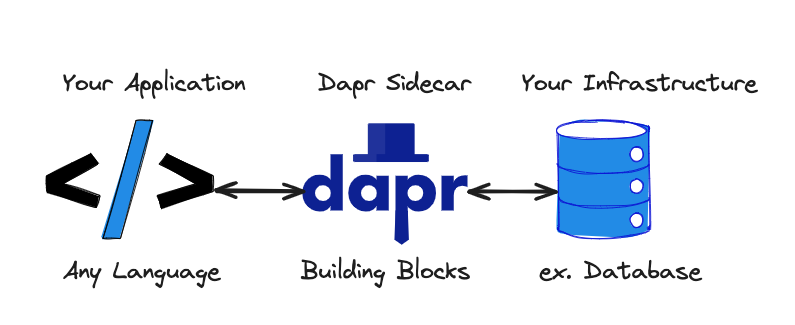
Your service
→ calls its local Dapr sidecar
Dapr sidecar
→ talks to other services or infrastructureThat local sidecar is important.
From your service’s point of view, Dapr is nearby. Your code can call Dapr over localhost using HTTP or gRPC. Then Dapr handles the distributed-system concern behind the scenes.
For example, your service might say:
Save this value as state.
Call the inventory service.
Publish this event.
Read this secret.Your service sends that request to its Dapr sidecar.
The sidecar then works out how to complete it using the configured Dapr component.
That component might point to Redis in local development, Azure Cosmos DB in Azure, Azure Service Bus for messaging, or Azure Key Vault for secrets.
The point is not that your code knows all those systems.
The point is that Dapr knows how to talk to them through configuration.
This is why the sidecar model matters:
Your service keeps the business logic.
Dapr handles more of the distributed-system plumbing.In a microservices application, each service can have its own Dapr sidecar.
So an Order Service might talk to its local Dapr sidecar, and that sidecar can invoke the Inventory Service through Dapr. The Inventory Service also has its own sidecar. Neither service needs to hard-code the other service’s IP address.
The mental model is:
Order Service
→ Order Dapr sidecar
→ Inventory Dapr sidecar
→ Inventory ServiceThat is the second key idea.
Dapr is not a library you hide deep inside one codebase.
It is a runtime that sits beside your services and gives them a consistent way to use distributed-system capabilities.
Dapr Building Blocks, Kept Simple
Dapr gives you a set of building blocks for common distributed-system problems.
You do not need to use all of them at once.
Most teams start with one or two, then add more as the application needs more capabilities.
The building blocks look like this:
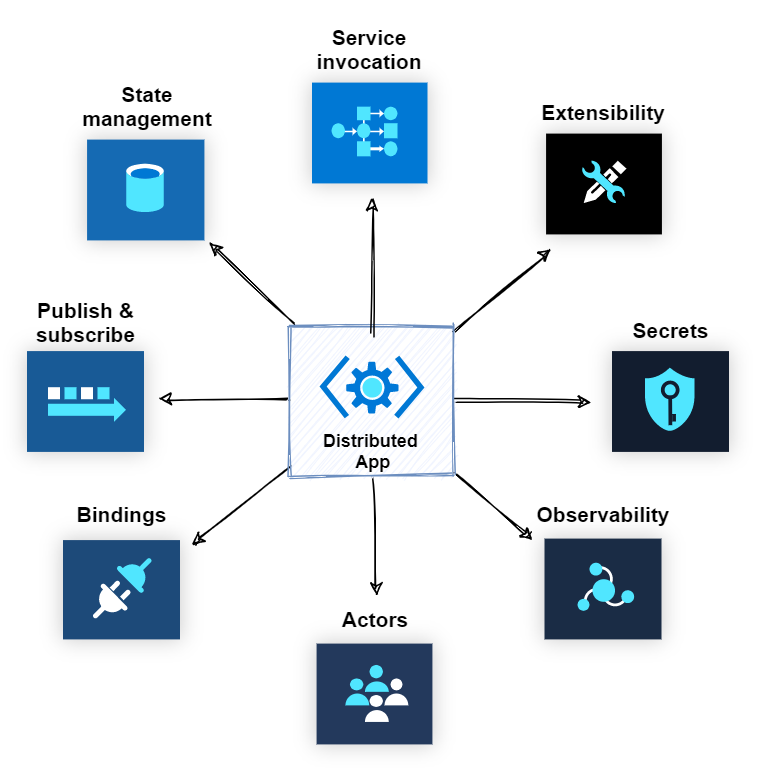
Each building block gives your application a consistent API for a specific kind of work.
For example:
Service invocation
→ call another service by name
State management
→ save and retrieve application state
Publish and subscribe
→ publish events and let other services react
Bindings
→ connect to external systems and triggers
Secrets
→ read secrets from a configured secret store
Observability
→ collect traces, metrics, and logs
Actors
→ build stateful, entity-based services
Extensibility
→ plug in custom components when neededThe important point is not that every application needs every building block.
The important point is that Dapr gives you a consistent way to use these capabilities when you need them.
There is also one more idea that makes Dapr powerful: building blocks and components are not the same thing.
A building block is the API your application uses.
A component is the configured backend Dapr connects to.
For example:
State management building block
→ your app calls Dapr’s state API
State store component
→ Dapr connects that API to Redis, Cosmos DB, PostgreSQL, or another state storeThe same idea applies to pub/sub:
Pub/sub building block
→ your app publishes or subscribes using Dapr’s pub/sub API
Pub/sub component
→ Dapr connects that API to Redis, Azure Service Bus, Kafka, or another message brokerThat separation matters.
Your application code can use the same Dapr API while the backend changes behind it.
Locally, you might use Redis.
In Azure, you might use Cosmos DB for state or Azure Service Bus for messaging.
The code does not need to be rewritten around a different SDK every time the infrastructure changes.
That is the real value of the building-block model.
Dapr does not just give you features.
It gives your services a consistent way to use distributed-system capabilities without tightly coupling the application code to every infrastructure choice.
Where Dapr Fits
At this point, it is worth being clear about what Dapr is and what it is not.
Dapr is not Kubernetes.
Kubernetes is an orchestration platform. It schedules containers, keeps workloads running, handles deployments, and manages cluster resources.
Dapr does not replace that.
Dapr can run on Kubernetes, but its job is different. It gives your application services APIs for distributed-system capabilities such as service invocation, state, pub/sub, secrets, and observability.
Dapr is also not a service mesh.
A service mesh focuses on network traffic between services: routing, traffic policy, mutual TLS, retries, telemetry, and service-to-service communication at the network layer.
Dapr overlaps with some of those concerns, especially service invocation, but its purpose is broader and more developer-facing. Dapr gives your application APIs for calling services, saving state, publishing events, reading secrets, and connecting to external systems.
Dapr is not an application framework either.
It does not force you to write your service in a specific language or framework. Your service can be written in Python, JavaScript, .NET, Java, Go, or anything else that can talk over HTTP or gRPC.
And Dapr is not your database, message broker, or secret store.
Those systems still exist.
Dapr sits between your application and those systems. It gives your code a consistent API, while Dapr components connect that API to the real backend infrastructure.
So the distinction is:
Kubernetes or Azure Container Apps
→ runs and manages your services
Dapr
→ gives your services distributed-system APIs
Redis, Cosmos DB, Service Bus, Key Vault, Kafka, and others
→ provide the backend capabilities Dapr connects toThat is where Dapr fits.
It is a runtime layer beside your application, not the platform underneath it and not the infrastructure behind it.
The mental model is:
Your service
→ Dapr sidecar
→ Dapr component
→ backend infrastructureThat is why Dapr is useful.
It lets your code depend on a stable runtime API instead of being tightly coupled to every infrastructure decision from the start.
Where This Leads
You now have the core Dapr idea.
Microservices can help you split a large system into smaller services, but they also introduce distributed-system problems. Services need to call each other, store state, publish events, read secrets, emit telemetry, and connect to external systems.
Without a shared approach, each service can end up carrying too much infrastructure knowledge.
Dapr gives you a different model:
Your service
→ talks to its local Dapr sidecar
→ uses Dapr building block APIs
→ connects through Dapr components
→ reaches the backend infrastructureThat is the foundation.
Dapr is not trying to replace your application platform or your cloud services. It is trying to give your application code a consistent way to use distributed-system capabilities without rewriting the same infrastructure glue in every service.
In the next article, we will move from concepts to code.
We will build a small two-service application:
Order Service
→ calls Inventory Service through Dapr service invocation
Inventory Service
→ stores inventory quantities through Dapr state managementThat will let us see the two most important Dapr ideas in action:
Service invocation
→ one service calls another by app ID
State management
→ a service stores and retrieves state through DaprThe goal is simple: prove that your service can stay focused on business logic while Dapr handles more of the distributed-system plumbing around it.