Publisher/Subscriber Pattern in Azure: Decoupling Services with Events

Introduction: The Tight Coupling Problem
Splitting a monolith into services does not automatically make the system loosely coupled.
You can have separate services, separate codebases, and separate teams, but still end up with a workflow where everything depends on everything else.
Imagine an e-commerce checkout.
A customer places an order. From the customer’s point of view, that is one action. Behind the scenes, several parts of the system may need to react. Stock needs to be updated. A shipment may need to be created. A confirmation email needs to be sent. Analytics needs to record the order. A fulfilment workflow may need to begin.
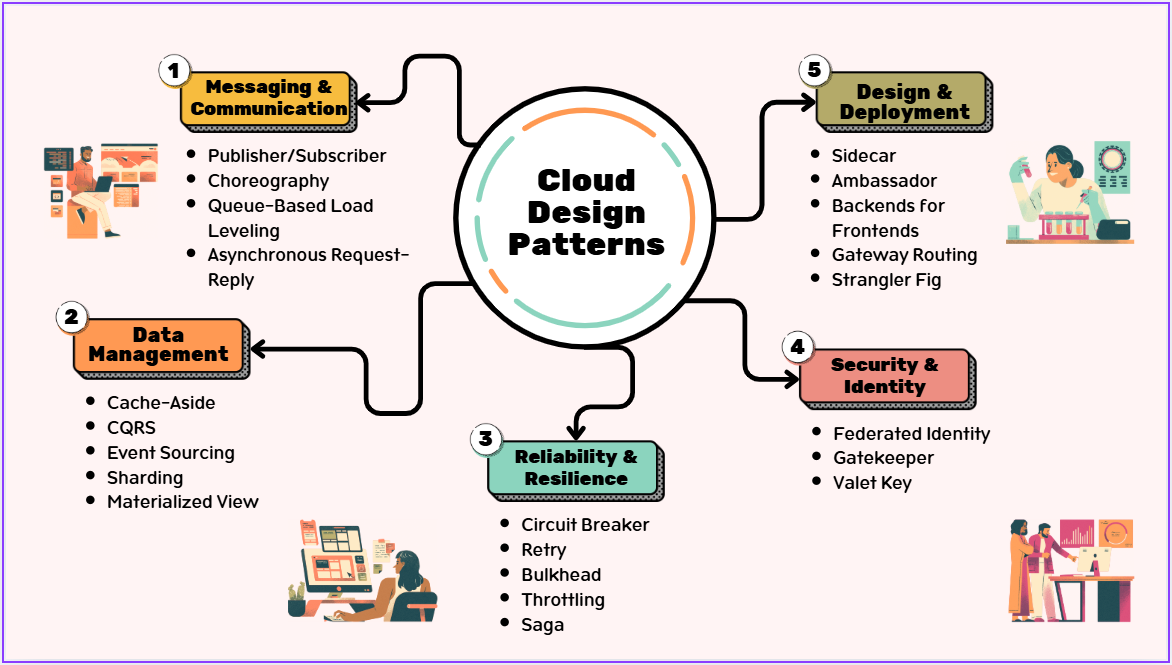
A simple design is to make the Order Service call each downstream service directly.
The Order Service calls Inventory. Then it calls Shipping. Then it calls Notifications. Then it calls Analytics. Then it calls any other service that needs to know about the order.
At first, this feels reasonable.
The flow is easy to follow. The Order Service controls the process. Each service is called in sequence, and the Order Service decides what happens next.
But this design creates a problem.
The Order Service is now coupled to every service it calls.
If the Shipping Service becomes slow, the order flow becomes slow. If the Notification Service is unavailable, the Order Service has to decide whether that should block the workflow. If the Analytics Service changes its API, the Order Service may need to change as well.
As more services are added, the Order Service starts to know too much.
It knows who needs to be called. It knows when they need to be called. It knows how their APIs work. It knows what to do when they fail.
The services are separate, but the workflow is still tightly connected.
That coupling shows up in three ways.
Runtime coupling means one slow or failing service can affect the rest of the flow.
Deployment coupling means a change in one service can force another service to change.
Knowledge coupling means the Order Service needs to understand too much about what every downstream service does.
This is one of the first problems teams run into when they move from a monolith to microservices.
The architecture has more services, but those services still depend on each other too directly.
The Publisher/Subscriber pattern exists to reduce that coupling.
Instead of the Order Service calling every interested service directly, it publishes an event that says something happened:
OrderPlaced
Other services subscribe to that event and react independently.
Inventory can update stock. Shipping can start fulfilment. Notifications can send the email. Analytics can record the order. The Order Service does not need to know every subscriber, and it does not need to wait for every reaction to finish.
That is the shift this article is about.
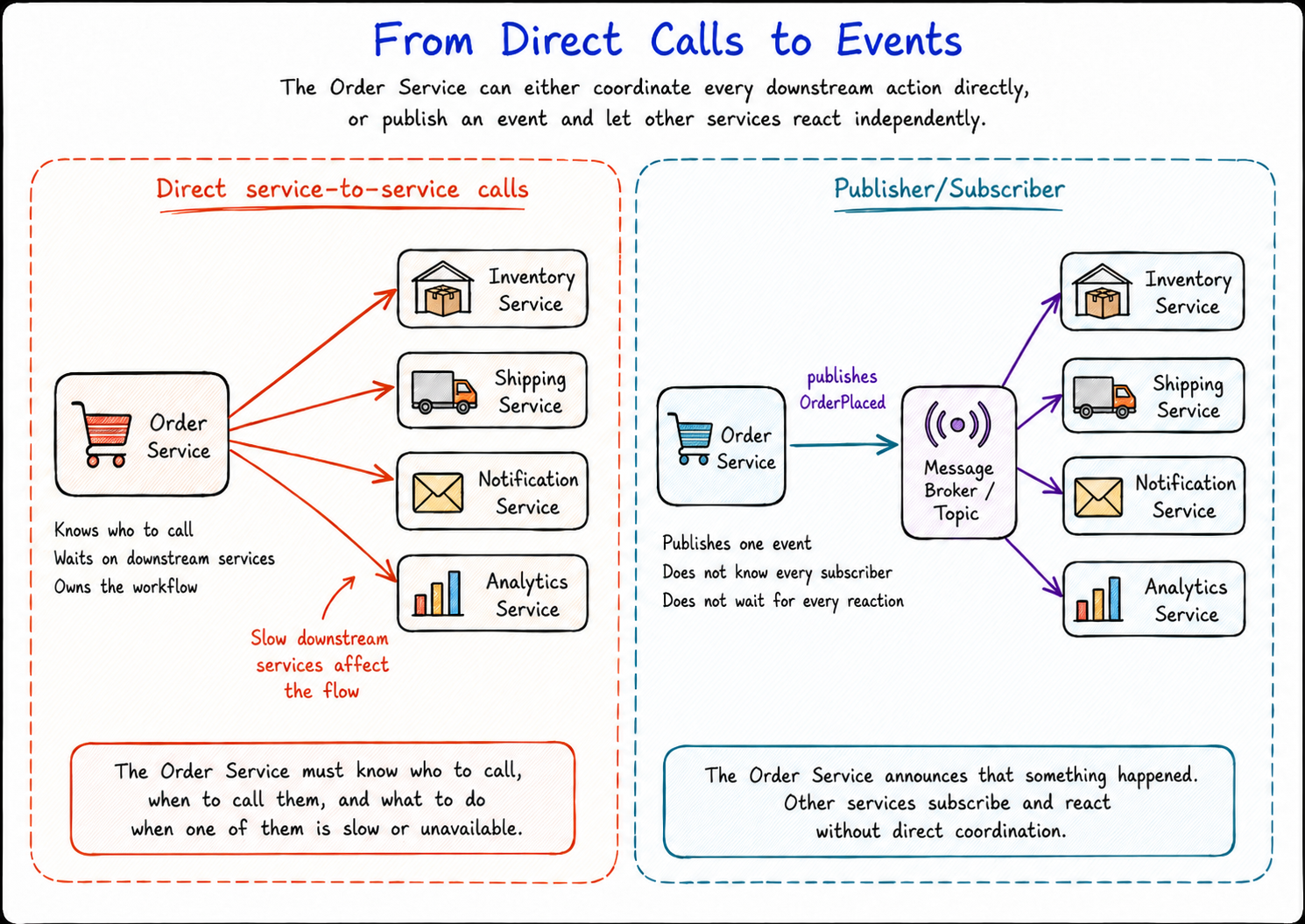
With direct service calls, services know about each other and often wait on each other.
With Publisher/Subscriber, one service publishes an event, and other services decide how to react.
Pub/Sub is not magic, and it is not the right pattern for every workflow. Some decisions still need direct request/response communication, especially when the caller needs an immediate answer.
But when the problem is tight coupling between services, Pub/Sub gives you a cleaner way to let services react without forcing the publisher to coordinate everyone else.
What Pub/Sub Changes
Pub/Sub changes who owns the workflow.
With direct service calls, the Order Service owns too much. It decides which services need to be called, when they need to be called, how their APIs work, and what should happen if one of them is slow or unavailable.
That makes the Order Service the coordinator for the whole downstream process.
It is no longer just responsible for accepting an order. It is also responsible for knowing how inventory, shipping, notifications, analytics, and any future service fit into the flow.
Pub/Sub changes that responsibility.
Instead of coordinating every downstream action, the Order Service publishes an event:
OrderPlaced
That event is not a command to a specific service.
It is a fact.
It says that an order has been accepted and placed. Something meaningful has happened in the business, and other parts of the system may care about it.
From there, each subscriber owns its own reaction.
The Inventory Service can react by updating stock or adjusting an inventory projection.
The Shipping Service can react by starting a fulfilment workflow.
The Notification Service can react by sending a confirmation email.
The Analytics Service can react by recording the order for reporting.
The Order Service does not need to coordinate those reactions directly. It does not need to know every subscriber. It does not need to wait for every subscriber to finish. It simply publishes the event and lets the interested services react.
That is the core change.
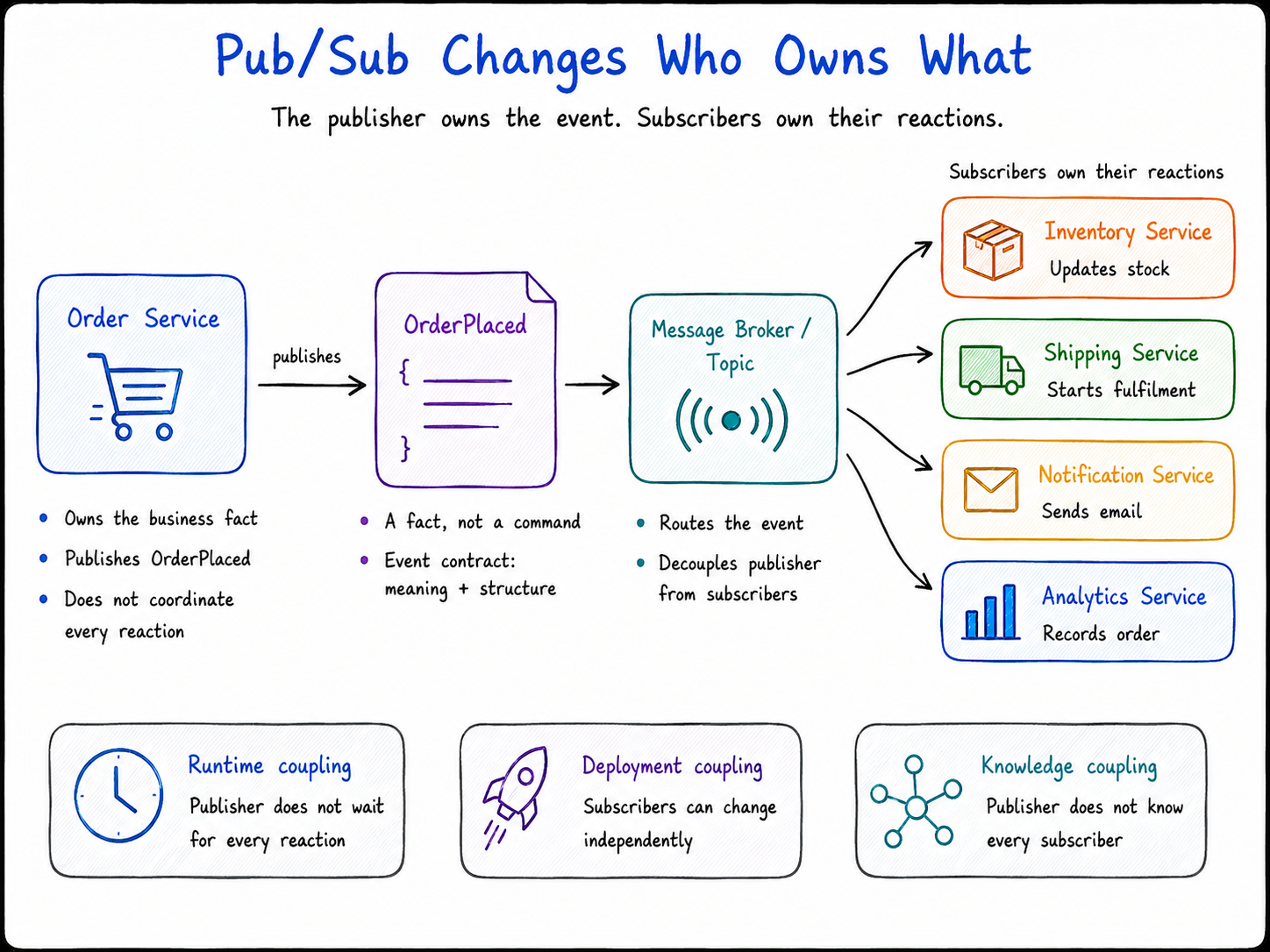
Pub/Sub does not make services stop depending on each other. It changes the shape of that dependency.
With direct calls, the dependency is direct and immediate. The Order Service knows the downstream services and often waits for them.
With Pub/Sub, the dependency moves through an event contract. The Order Service publishes OrderPlaced, and subscribers depend on the meaning and structure of that event rather than on the Order Service calling them directly.
That reduces three kinds of coupling.
Runtime coupling is reduced because the Order Service does not need to wait for every downstream reaction before continuing. If Analytics is slow, the order flow does not have to be slow because of it.
Deployment coupling is reduced because a subscriber can change its internal implementation without forcing the Order Service to change, as long as the event contract remains stable.
Knowledge coupling is reduced because the Order Service no longer needs to know every service that wants to react to an order. New subscribers can be added later without changing the publisher.
This is why Pub/Sub is useful in distributed systems.
It gives services a way to react to business events without forcing one service to coordinate every other service.
But it is still a trade-off.
The system becomes more asynchronous. Events need clear contracts. Subscribers need to handle retries and duplicate delivery. Failed messages need a recovery path. Some parts of the system may become eventually consistent instead of updating immediately.
So Pub/Sub does not remove complexity.
It moves complexity away from direct service coordination and into event design, message delivery, and subscriber responsibility.
That trade-off is usually worth it when the real problem is tight coupling between services.
The Shape of Pub/Sub
Pub/Sub has a simple shape: a publisher produces an event, a broker or topic receives it, and subscribers receive that event through their own subscriptions and react in their own way.
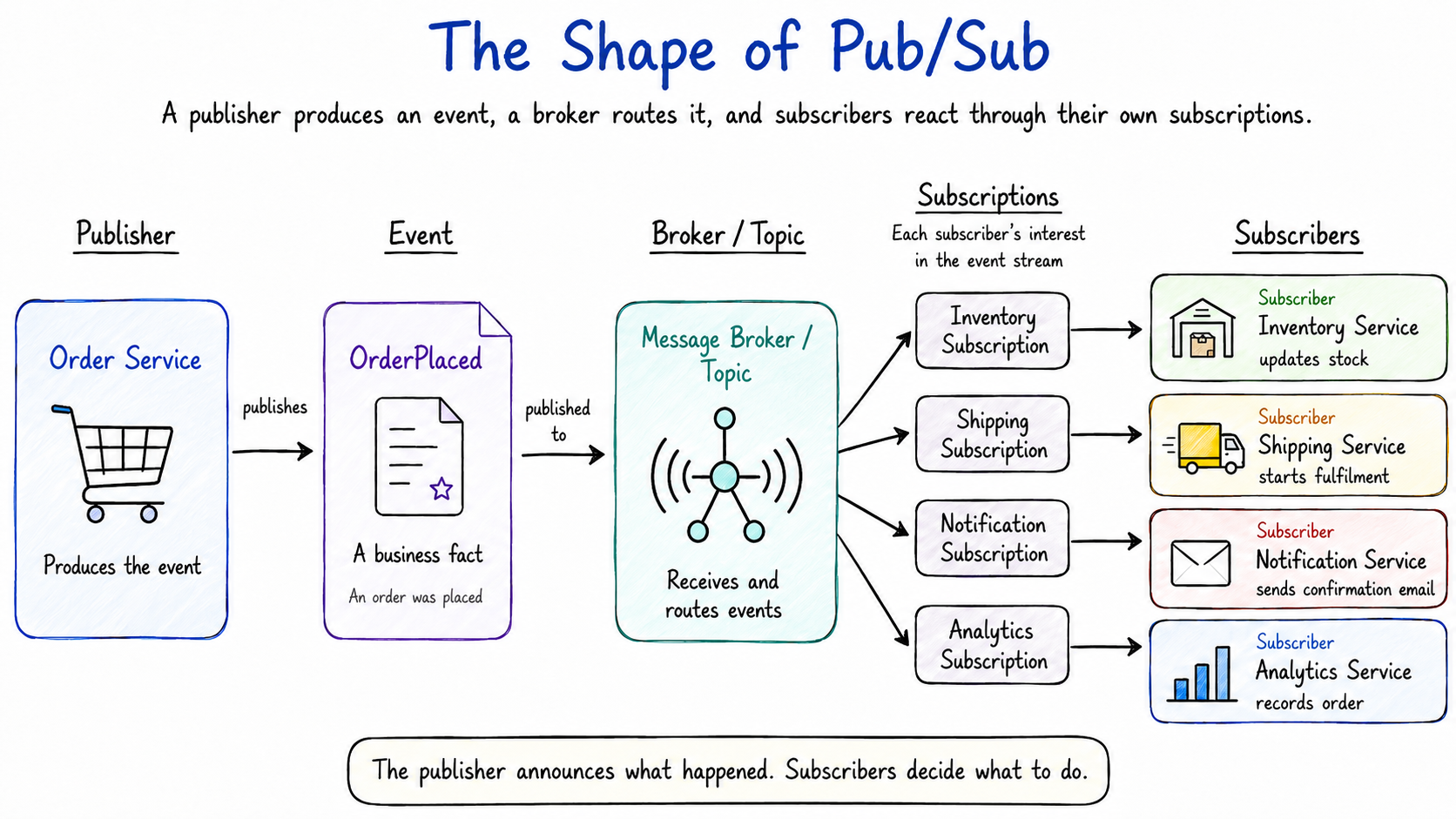
Different platforms use slightly different names, but most Pub/Sub systems are built around the same core pieces: publisher, event, broker or topic, subscriber, and subscription.
Publisher
The publisher is the service that announces that something happened.
In our example, the Order Service publishes OrderPlaced after an order has been accepted.
The publisher is responsible for producing a clear event. It should describe the business fact that happened and include enough information for other services to understand it.
Event
The event is the business fact being published.
OrderPlaced is an event because it describes something that has already happened.
In a direct-call design, the Order Service might tell the Notification Service exactly what to do by sending a command such as:
SendConfirmationEmail
That command is aimed at one specific service and one specific action.
In a Pub/Sub design, the Order Service publishes:
OrderPlaced
That event does not tell the Notification Service what to do. It simply says that an order was placed.
The Notification Service can receive that event and decide that its reaction is to send a confirmation email. The Shipping Service can receive the same event and decide that its reaction is to start fulfilment. Analytics can receive the same event and record the order for reporting.
That is the difference.
A command asks for a specific action.
An event describes something that happened.
Pub/Sub works best when the publisher announces a fact and subscribers decide what that fact means for their own part of the system.
Broker or topic
The broker is the infrastructure in the middle.
It receives events from publishers and makes them available to subscribers.
Depending on the platform, you may hear words like broker, topic, stream, subject, or event type. The names change, but the role is similar. This is the place where events are published so interested consumers can receive them.
The broker is what separates the publisher from the subscribers at runtime.
Subscriber
A subscriber is a service that receives an event and reacts to it.
Inventory may update stock. Notifications may send an email. Analytics may record the order. Shipping may start fulfilment.
Each subscriber handles its own work based on the event it receives.
The subscriber does not own the event itself. It owns its reaction to the event.
That distinction matters because several subscribers can receive the same event and do different things with it.
Subscription
A subscription is the subscriber’s path into the event stream.
It represents that subscriber’s interest in a particular topic or set of events. When a matching event is published, the broker makes that event available through the subscription so the subscriber can receive and process it.
You can think of a subscription as a queue-like inbox for one logical subscriber.
The Notification Service may have a Notification Subscription. The Shipping Service may have a Shipping Subscription. The Analytics Service may have an Analytics Subscription. Each subscription gives that service its own place to receive events, process them, retry them, or fall behind if needed.
You might notice something important in the diagram: Inventory, Shipping, Notifications, and Analytics do not all read from one shared subscription. They each have their own subscription.
That is deliberate.
The same OrderPlaced event may need to be processed by several different services. If all those services read from one shared subscription, they would usually compete for the same message. One service could receive and complete the message, and the others would not get their own copy to process.
Inventory, Shipping, Notifications, and Analytics are different logical subscribers. They each need their own copy of the event and their own processing path.
That is why the diagram shows separate subscriptions for Inventory, Shipping, Notifications, and Analytics.
If Analytics is offline, its subscription can fall behind without blocking Shipping or Notifications. If Shipping fails to process its copy of the event, that does not stop Analytics from processing its own copy.
So the pattern comes down to this:
Publisher: produces the event. Event: describes what happened. Broker or topic: makes the event available. Subscriber: reacts to the event. Subscription: gives a subscriber its own path for receiving and processing events.
The publisher announces what happened. Subscribers decide what to do.
The next practical question is: if we are building this on Azure, which service should play the broker role?
This is where the tool choice matters. Pub/Sub is the pattern, but Azure gives us more than one way to implement it. Service Bus, Event Grid, and Event Hubs can all support event-driven designs, but they are built for different kinds of messaging problems.
Pub/Sub in Azure: Choosing the Right Tool
There is no single “Pub/Sub service” in Azure that fits every situation.
That can feel confusing at first, but it makes more sense if you keep the pattern separate from the tool.
The pattern is Pub/Sub: a publisher announces that something happened, and subscribers react.
The tool is the Azure service you choose to implement that pattern.
In Azure, the three services teams usually reach for when implementing this kind of Pub/Sub model are Azure Service Bus, Azure Event Grid, and Azure Event Hubs. They can all support event-driven designs, but they are built for different kinds of problems.
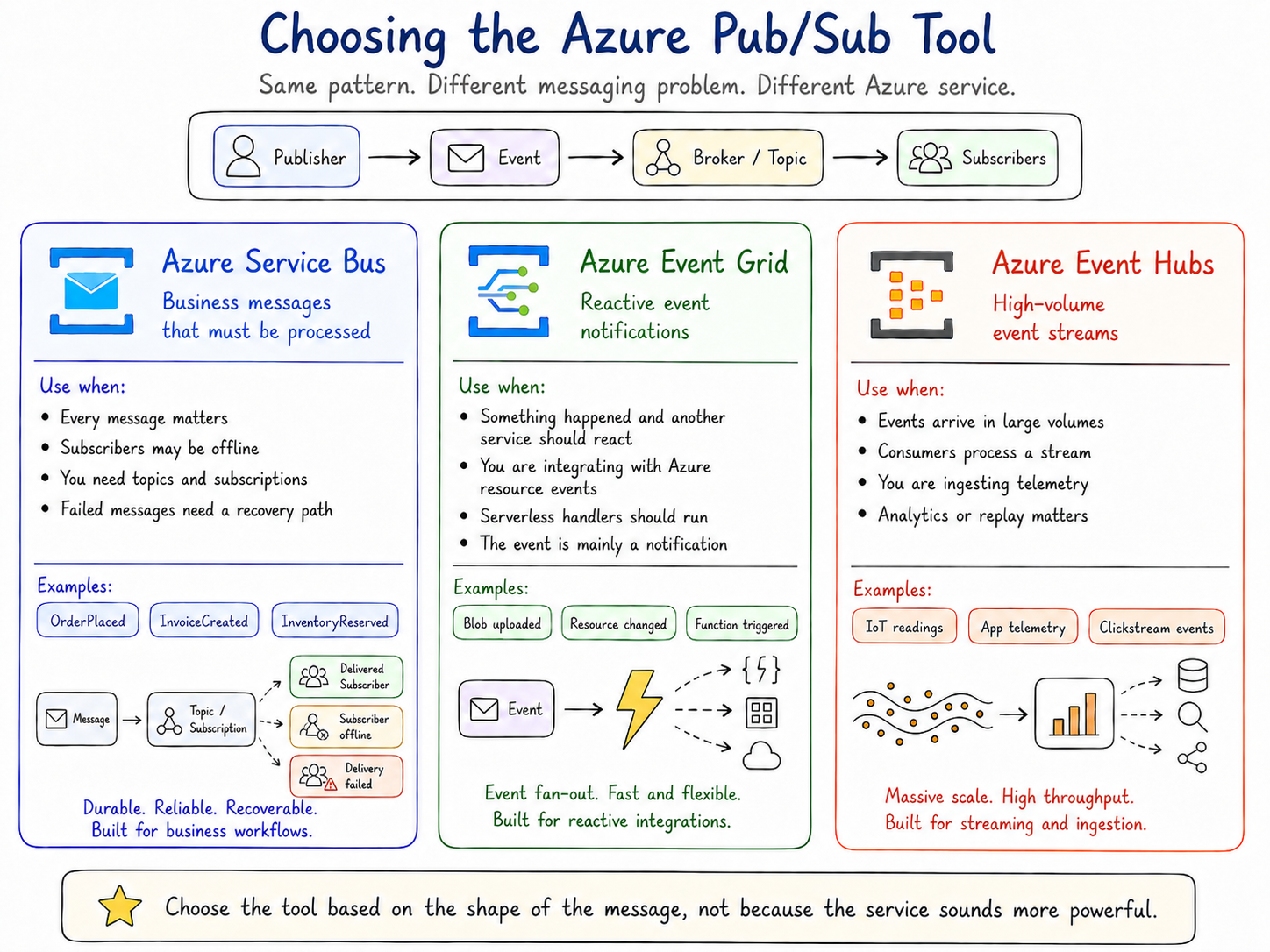
Azure Service Bus: business messages that need reliable processing
Azure Service Bus is usually the best place to start when the message represents business work that must be processed reliably.
Think about events like:
OrderPlaced
PaymentProcessed
InvoiceCreated
InventoryReserved
These are not just casual notifications. They represent business activity that a system needs to process carefully.
For example, if an OrderPlaced event is published and the Shipping Service is temporarily offline, you probably do not want that message to disappear. You want the message to wait until Shipping can process it, or move somewhere safe if it repeatedly fails.
That is where Service Bus fits well.
Service Bus supports queues, topics, and subscriptions, which makes it a natural fit for business messaging and durable publish/subscribe workflows. It also supports dead-letter queues, which give failed messages somewhere to go when they cannot be processed successfully.
Use Service Bus when:
Business messages must be processed reliably. Subscribers may be temporarily offline. You need topics and subscriptions. You need dead-letter handling for failed messages. You are modelling workflow-style business events.
For the e-commerce example in this article, OrderPlaced is a strong Service Bus candidate because the event represents business work that should not be casually lost.
Azure Event Grid: reactive event notifications
Azure Event Grid is a better fit when the event is mainly a notification that something happened and another service needs to react.
For example:
A file was uploaded to Blob Storage. A resource changed in Azure. A serverless function should run after an event. An application needs to react to events from Azure services or custom sources.
Event Grid is a fully managed publish/subscribe service for message distribution and event-driven architectures. It is commonly used for reactive integrations, serverless event handlers, and Azure resource events.
Use Event Grid when:
You want services to react to events quickly. The event is mainly a notification. You are integrating with Azure resource events. You are building event-driven serverless flows.
The key distinction is not “Service Bus is reliable and Event Grid is not.” That is too simplistic. The distinction is the shape of the problem.
Service Bus is usually better for business message processing.
Event Grid is usually better for event notification and reactive routing.
Azure Event Hubs: high-volume event streams
Azure Event Hubs is built for streaming.
It is designed for large volumes of events, telemetry, and real-time data ingestion. Microsoft describes Event Hubs as a fully managed real-time data streaming platform that can ingest millions of events per second with low latency.
Think about workloads like:
Application telemetry. IoT sensor readings. Clickstream events. Audit streams. Real-time analytics feeds.
In these scenarios, you are not usually thinking about one business message that one subscriber must process. You are thinking about a continuous stream of events that consumers read and process over time.
Use Event Hubs when:
You need very high throughput. You are ingesting telemetry or streaming data. Consumers process events as a stream. You care about analytics, replay, and stream processing.
Event Hubs can still be part of an event-driven architecture, but it solves a different problem from ordinary business messaging.
A simple way to choose
Start with the shape of the message.
If the message represents business work that must be processed, start with Azure Service Bus.
If the message is a notification that something happened and services need to react, look at Azure Event Grid.
If the message is part of a high-volume stream of telemetry or events, look at Azure Event Hubs.
That gives us the tool layer:
Problem: services are too tightly coupled. Pattern: Pub/Sub. Tools: Service Bus, Event Grid, or Event Hubs, depending on the shape of the event.
The important part is not choosing the most powerful service.
The important part is choosing the service that matches the problem.
Where This Leads: Retry
Pub/Sub gives us a cleaner way for services to communicate.
The publisher announces that something happened. The broker makes the event available. Subscribers react independently. In Azure, that might involve Service Bus, Event Grid, or Event Hubs, depending on the shape of the message.
But choosing the right Pub/Sub tool does not remove the next problem.
Events still have to be processed.
A subscriber may receive an event and then fail while doing its work. The database may be unavailable. A downstream API may time out. A service may be throttled. The network may drop for a moment. The message itself may be valid, but the system is not ready to process it right now.
That leads to the next design question:
What should a subscriber do when processing fails?
Trying again can help when the failure is temporary. But retrying too quickly, too often, or without limits can make a struggling system even worse.
That is where the Retry pattern comes in.
Retry is about handling temporary failures carefully. It helps a service try again when the problem may go away, but it also forces us to think about delay, limits, backoff, duplicate processing, and when to stop.
That is the next pattern we will look at.
Pub/Sub helps services communicate without being tightly coupled. Retry helps them deal with the failures that happen when those messages are processed.