Why Cloud-Native Architecture Patterns Exist
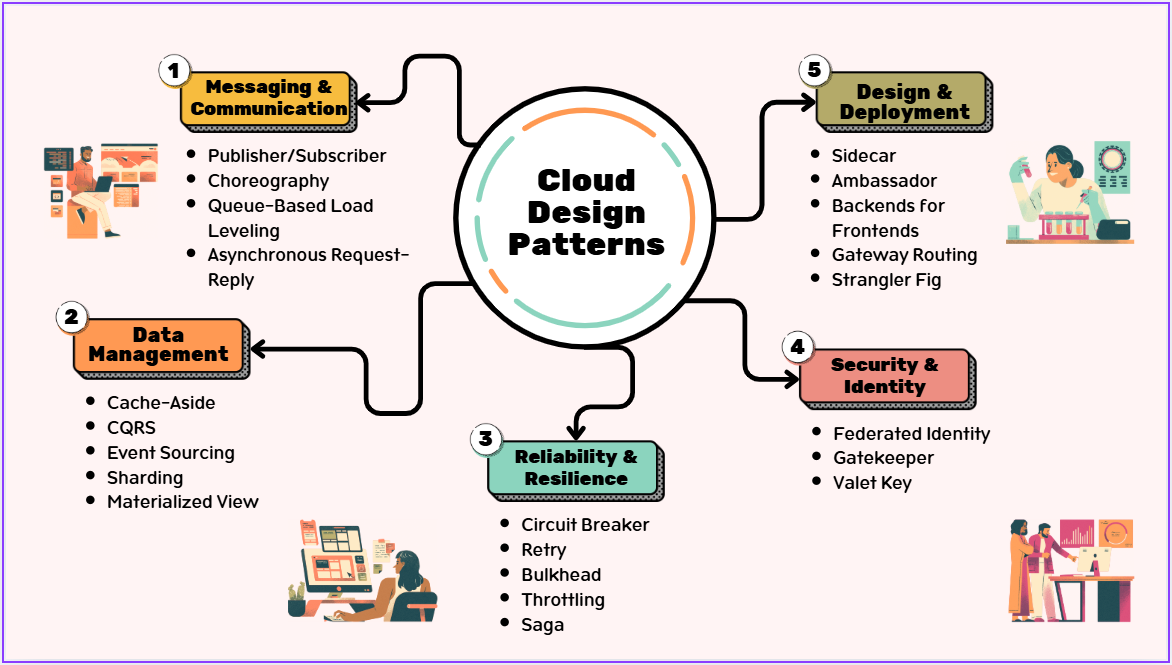

Introduction
For a while, building applications felt manageable.
You had one application, one database, and a small number of servers to think about. Most of the system lived in one codebase. When something broke, you knew where to start. A slow page meant checking the application logs. A bad query meant tracing the request from the code to the database. A failed release was painful, but at least the shape of the problem was visible.
That simplicity did not last.
As the product grew, the application that once felt simple became a monolith. More features, more teams, and more business logic ended up inside the same deployment unit. The codebase became harder for any one team to understand properly. Multiple teams changed the same parts of the system at the same time. A small fix in billing could break checkout. A change to inventory could affect search. Every release became risky because shipping one feature meant testing and deploying the whole application.
The problem was no longer just technical. It was organisational.
Teams needed to move independently. Different parts of the product needed to scale at different rates. A fix to payments should not have to wait for a search release. A spike in checkout traffic should not require scaling the entire application. The system needed smaller pieces that could be owned, changed, deployed, and scaled separately.
So the application was split into services.
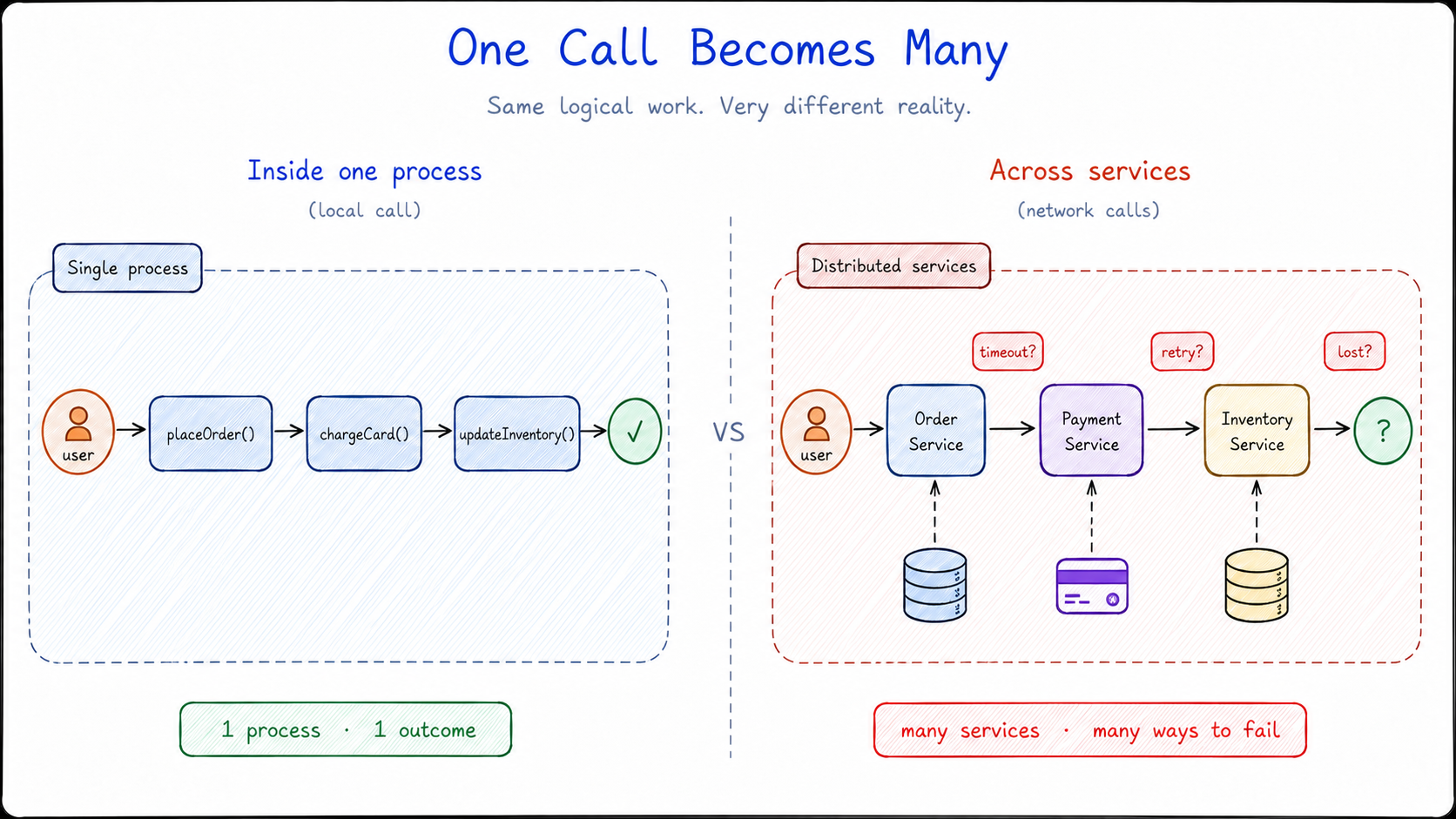
Checkout became an order service. Payments became a payment service. Inventory became an inventory service. Each part now had clearer ownership, its own runtime, and its own release path.
At first, this felt like progress, because it was.
But the complexity had not disappeared. It had moved.
The work that used to happen inside one process was now spread across several services. Placing an order still looked like one action from the user’s point of view, but behind the scenes it had become a chain of calls across service boundaries.
That changed the kind of problems engineers had to solve.
Inside one process, a call is usually direct and predictable. Across services, the network becomes part of the application. A service can be slow, unavailable, overloaded, or unsure whether the last request actually completed. One part of the system can now affect another part in ways that are harder to see and harder to control.
Once a system is distributed, the hard parts are no longer only inside the codebase. They are in the relationships between services: how they communicate, how they fail, how they share data, how they handle load, and how engineers understand what happened when something goes wrong.
That is the world cloud-native architecture patterns are designed for.
The Problems That Keep Coming Back
Once an application is split across services, the same problems start showing up again and again.
They may look different in each system, but underneath they usually come back to the same pressures: services need to communicate, failures need to be contained, data needs to stay understandable, traffic needs to be managed, and engineers need enough visibility to know what happened.
These are the problems cloud-native architecture patterns are built around.
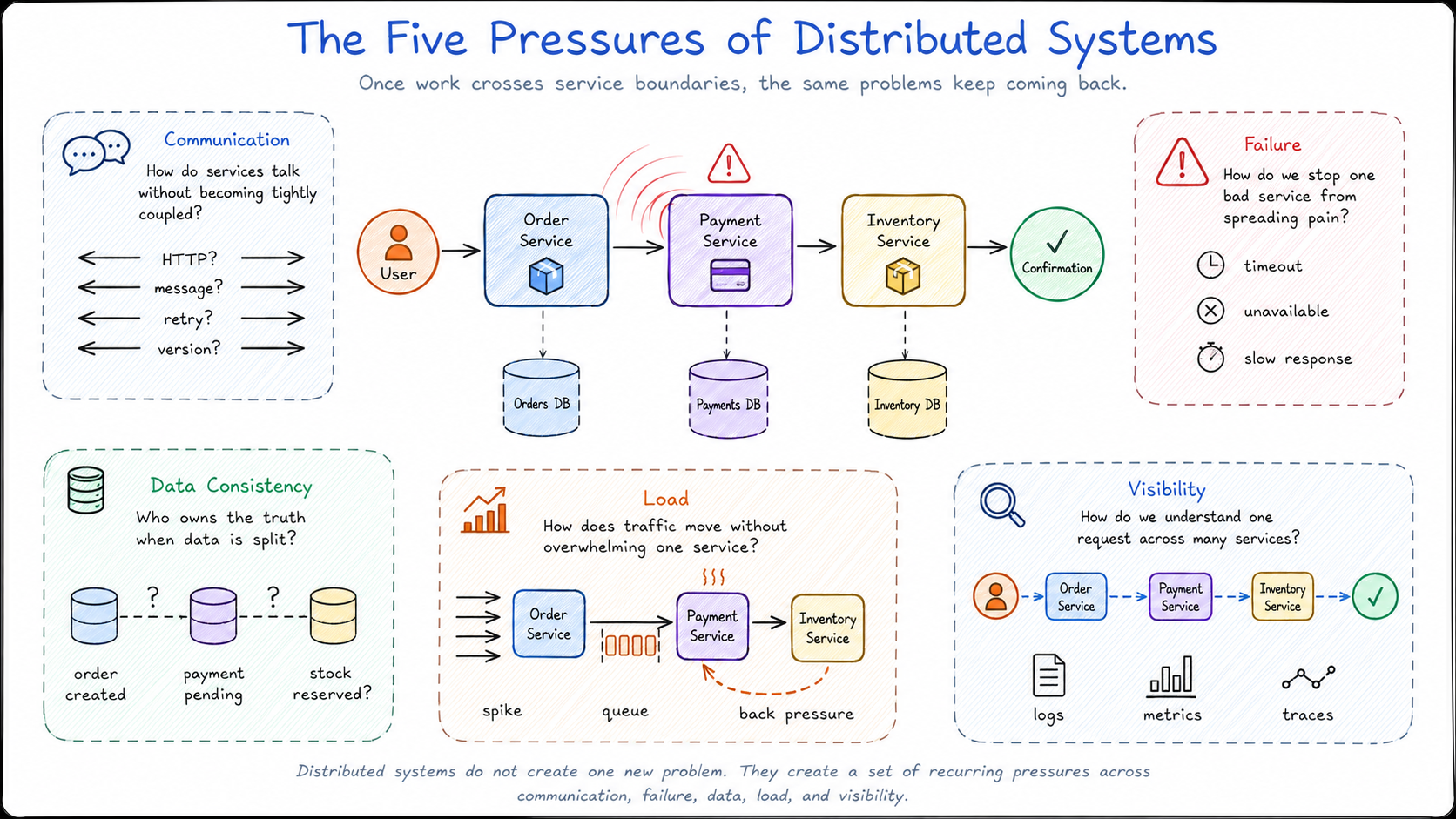
Communication: services still need to talk
Splitting a system into services does not remove communication. It usually creates more of it.
In a monolith, one part of the application can call another part directly. The call stays inside the same process. It uses the same memory space. It usually returns, throws an error, or fails in a way the application can see immediately.
In a distributed system, that same interaction crosses a service boundary.
Now the call may involve HTTP, messaging, authentication, retries, timeouts, serialization, versioning, and separate deployment lifecycles. A simple “call this function” has become “communicate with another system over a network.”
The question is not whether services need to talk. They do.
The question is how they talk without becoming tightly coupled to each other.
That is why communication becomes an architectural decision.
Failure: one bad service can affect the others
Failure is not new. Systems failed before microservices.
What changes in a distributed system is how failure spreads.
A recommendation service can slow down product pages. A payment service can block checkout. An inventory service can make orders wait. The service that fails may not be the service the user thinks they are using, but the user still feels the impact.
This is why “just make every service reliable” is not enough.
Distributed systems will fail. Services will slow down. Networks will drop calls. Dependencies will become unavailable. The design question is how much damage one failure is allowed to cause.
The goal is not to pretend failure will not happen.
The goal is to stop one failure from turning into a system-wide problem.
Data consistency: no single database owns everything anymore
In a monolith, the database often acts as the centre of truth.
If placing an order means creating an order record, taking a payment, reducing stock, and updating shipping, those changes may happen inside one database transaction. The application can treat the whole thing as one unit of work.
Once the system is split into services, that model becomes harder.
The order service owns orders. The payment service owns payments. The inventory service owns stock. The shipping service owns delivery details. Each service may be correct about its own data, but no single database owns the full business process anymore.
That creates a different kind of problem.
What happens if the order is created but payment fails? What happens if payment succeeds but stock cannot be reserved? What happens if one service has updated, but another service has not caught up yet?
This is where distributed systems force you to think carefully about consistency, coordination, and recovery.
Load: scaling one service is not the whole story
One of the reasons teams split systems into services is so different parts can scale independently.
That is useful, but it does not remove the load problem. It changes where the load problem appears.
A spike in checkout traffic may overload the payment service. A burst of product views may overwhelm recommendations. A slow downstream service may cause requests to pile up in the services calling it.
Scaling is no longer just about adding more capacity.
It is about controlling how work moves through the system.
Sometimes that means scaling a service. Sometimes it means queuing work. Sometimes it means applying back pressure. Sometimes it means failing fast instead of letting requests pile up until everything becomes slow.
In a distributed system, load is not only a capacity problem. It is a flow problem.
Visibility: the story is spread across services
In a monolith, debugging is not always easy, but at least the story usually lives in one place.
A request comes in. The application handles it. Logs, exceptions, database calls, and performance issues are usually connected through the same runtime.
In a distributed system, the user still sees one action.
Behind the scenes, that action may cross five services, three databases, a queue, an API gateway, and a background worker. Each part may have its own logs, metrics, errors, and timing.
The user says, “Checkout failed.”
The engineer has to work out whether the issue started in the order service, the payment service, the inventory service, the network, the database, the message broker, or somewhere in between.
Without visibility, distributed systems become guesswork.
You need logs, metrics, and traces that help you reconstruct what happened across service boundaries.
This is why patterns matter
These five pressures are why cloud-native architecture patterns matter.
They give us repeatable ways to deal with problems that keep coming back: how services communicate, how failures are contained, how data is coordinated, how load is controlled, and how behaviour is understood across the system.
The patterns are not the starting point.
The pressures are.
What Are Cloud-Native Architecture Patterns?
Cloud-native architecture patterns are reusable ways of dealing with the problems that appear when systems are split across services.
That is the simplest way to think about them.
We do not start with, “I want to use Pub/Sub.” We start with a problem: our services are too tightly coupled. One service needs to tell other parts of the system that something happened, but we do not want every service calling every other service directly.
That is when a messaging pattern like Pub/Sub starts to make sense.
We do not start with, “I want to use a Circuit Breaker.” We start with a problem: one slow or unhealthy service is causing other services to slow down with it. Requests are piling up. Threads are being held open. The failure is spreading.
That is when a resilience pattern like Circuit Breaker starts to make sense.
We do not start with, “I want to use Saga.” We start with a problem: one business process now crosses multiple services, and each service owns its own data. Creating an order, taking a payment, reserving stock, and arranging shipping may all be part of one user action, but they no longer happen inside one database transaction.
That is when a coordination pattern like Saga starts to make sense.
This is the important point: patterns are responses to pressure.
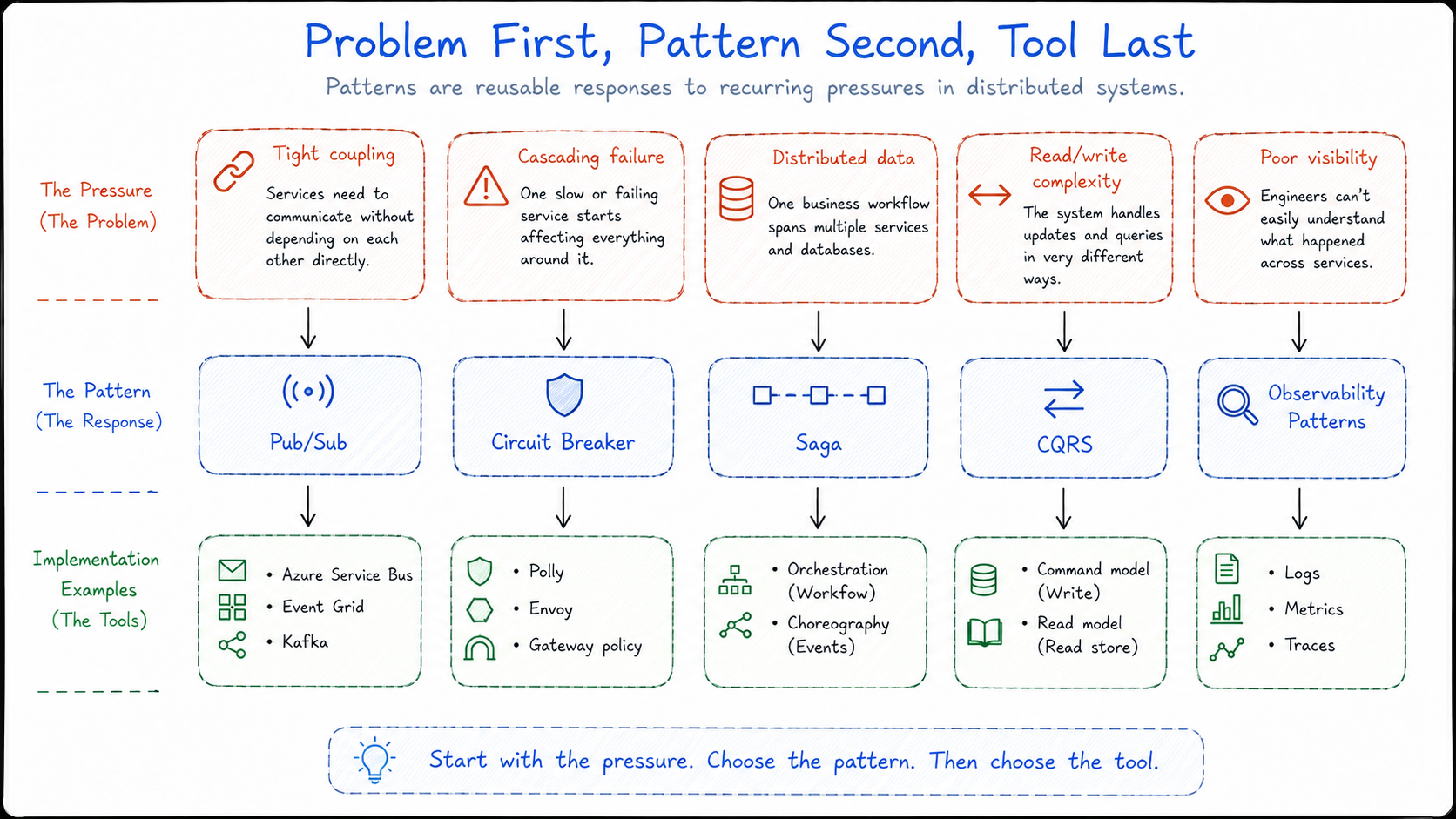
They are not decorations you add to make an architecture look more advanced. They are not a checklist of things every cloud-native system must include. They are ways of handling problems that keep showing up once services have to communicate, fail, recover, share data, handle load, and remain understandable across service boundaries.
A pattern is also not the same thing as a product.
Pub/Sub is a pattern. Azure Service Bus, Event Grid, Kafka, RabbitMQ, and other messaging technologies are possible ways to implement parts of that pattern.
Circuit Breaker is a pattern. A library, service mesh, gateway, or custom policy might help you implement it.
CQRS is a pattern. It is not a database product. It is a way of separating how a system handles writes from how it serves reads.
That distinction matters because tools change. Platforms change. The underlying problems stay familiar.
The same communication problem can show up in a .NET application running on Azure, a Java application running on Kubernetes, or a serverless application using managed cloud services. The implementation may look different in each environment, but the architectural pressure is the same.
That is why patterns are useful. They give engineers a shared language for problems that are bigger than one framework or one cloud provider.
But patterns are not free.
Every pattern solves one problem by introducing a different kind of complexity. Pub/Sub can reduce direct coupling between services, but it also introduces message delivery, ordering, retries, idempotency, and eventual consistency. Retry can make a system more resilient to temporary failures, but careless retries can make an overloaded service even worse. CQRS can make read models faster and simpler, but it usually means duplicating data and accepting that not every view updates instantly.
So the goal is not to use as many patterns as possible.
The goal is to recognise the pressure in the system, understand the trade-off, and choose the pattern that fits the problem.
That is the mindset behind cloud-native architecture patterns: problem first, pattern second, tool last.
Start With the Pressure
The easiest mistake to make with architecture patterns is to start with the pattern name.
A team hears about Pub/Sub, so they look for somewhere to use it. They hear about CQRS, so they start wondering whether every service needs separate read and write models. They hear about Circuit Breaker, so they add one without first asking what kind of failure they are trying to contain.
That usually puts the conversation in the wrong order.
Start with the pressure in the system.
Are services calling each other so directly that every change requires coordination? That is a communication and coupling problem.
Is one slow dependency causing requests to pile up across the system? That is a failure and load problem.
Is one business process spread across several services and databases? That is a consistency and coordination problem.
Are engineers struggling to understand what happened when a request crosses service boundaries? That is a visibility problem.
Once the pressure is clear, the pattern conversation becomes much more useful. You are no longer asking, “Should we use this pattern?” in the abstract. You are asking, “Does this pattern help with the pressure we actually have, and are we willing to accept the trade-offs it introduces?”
That is the practical way to think about cloud-native architecture patterns.
Problem first. Pattern second. Tool last.
Where We Go Next: Communication
The first pressure most teams feel is communication.
Once a system is split into services, those services still need to tell each other when something happens. An order is placed. A payment is received. Stock is reserved. A shipment is requested. The system still needs to work as one product, even though the work is now spread across multiple services.
The simple answer is direct service-to-service calls.
The order service calls payments. Payments calls fraud detection. The order service calls inventory. Inventory calls shipping. That can work for a while, but over time the system becomes harder to change. Every new workflow adds another dependency. Every new feature requires more coordination. One service starts knowing too much about what every other service needs to do.
That is a communication and coupling problem.
This is where Pub/Sub becomes useful.
Instead of one service calling every other service directly, it publishes an event that says something happened. Other services subscribe to the events they care about and react independently. The order service does not need to know every downstream action that should happen after an order is placed. It just publishes OrderPlaced, and the rest of the system responds.
That does not make the complexity disappear. Pub/Sub introduces its own trade-offs: message delivery, retries, ordering, idempotency, and eventual consistency all need to be handled carefully.
But that is exactly the point of this article.
We start with the pressure. Then we choose the pattern. Then we choose the tool.
In the next article, we will start with one of the most common pressures in distributed systems: services that need to communicate without becoming tightly coupled.